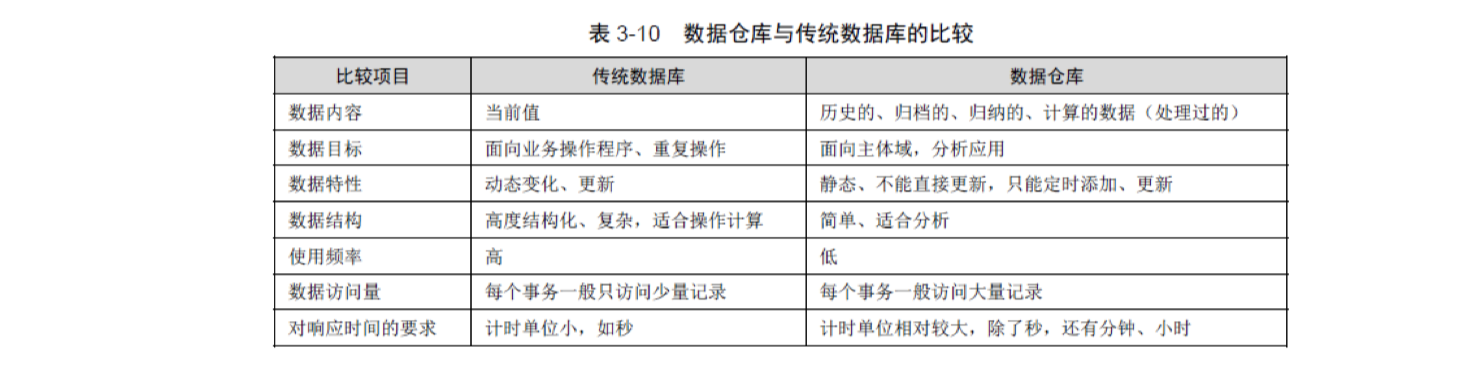
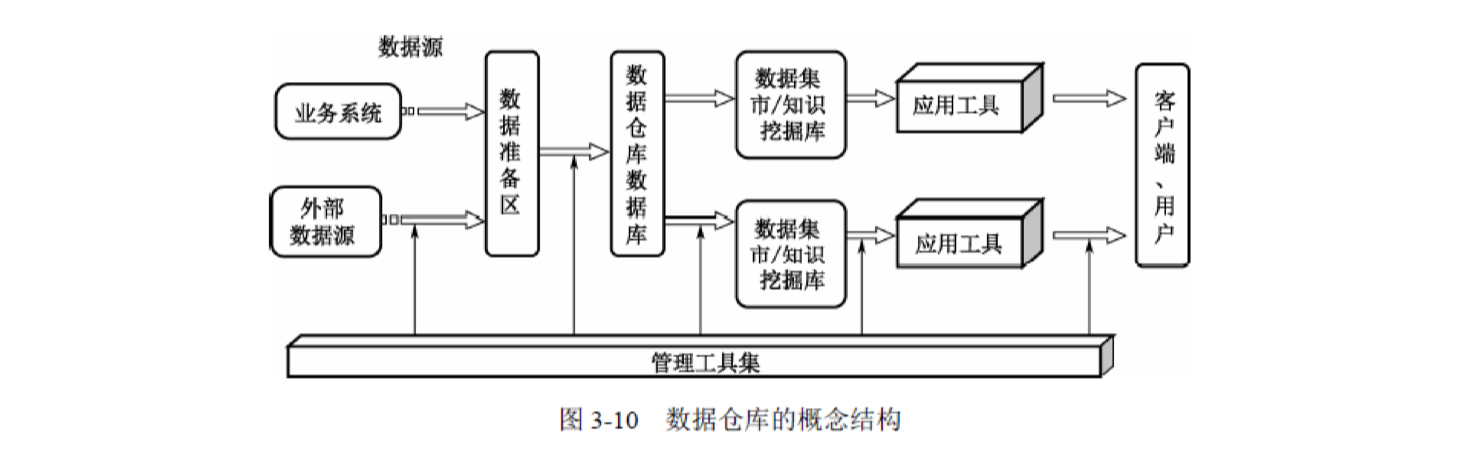
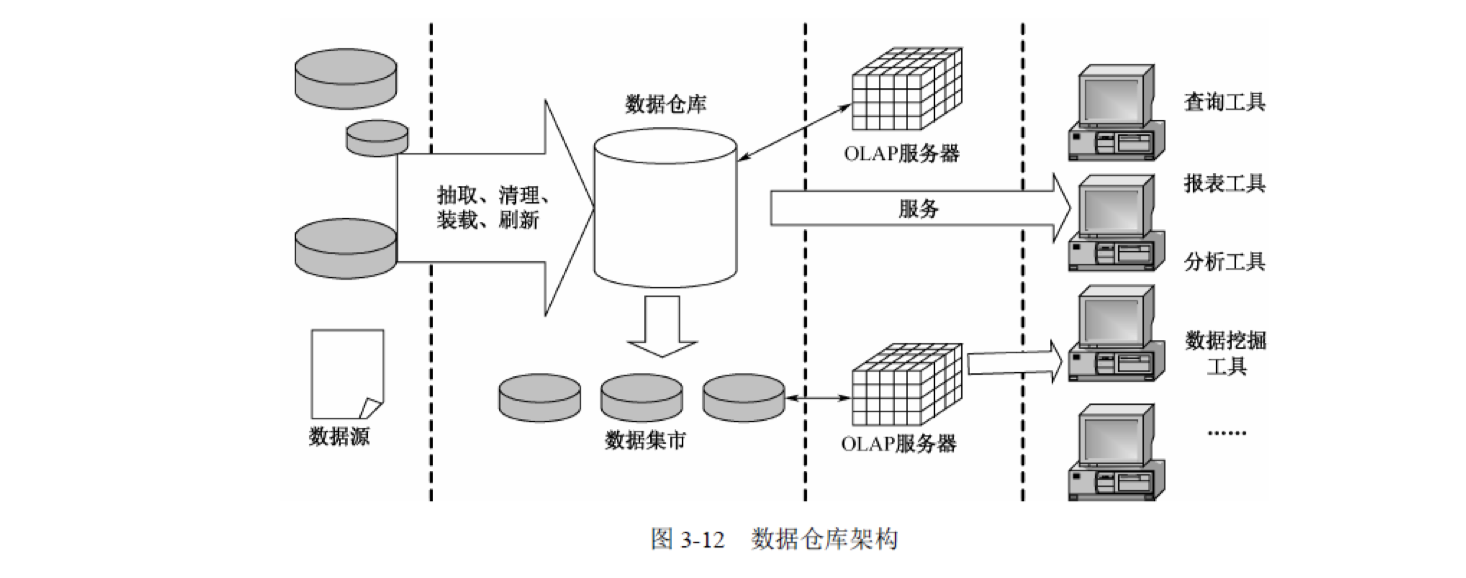
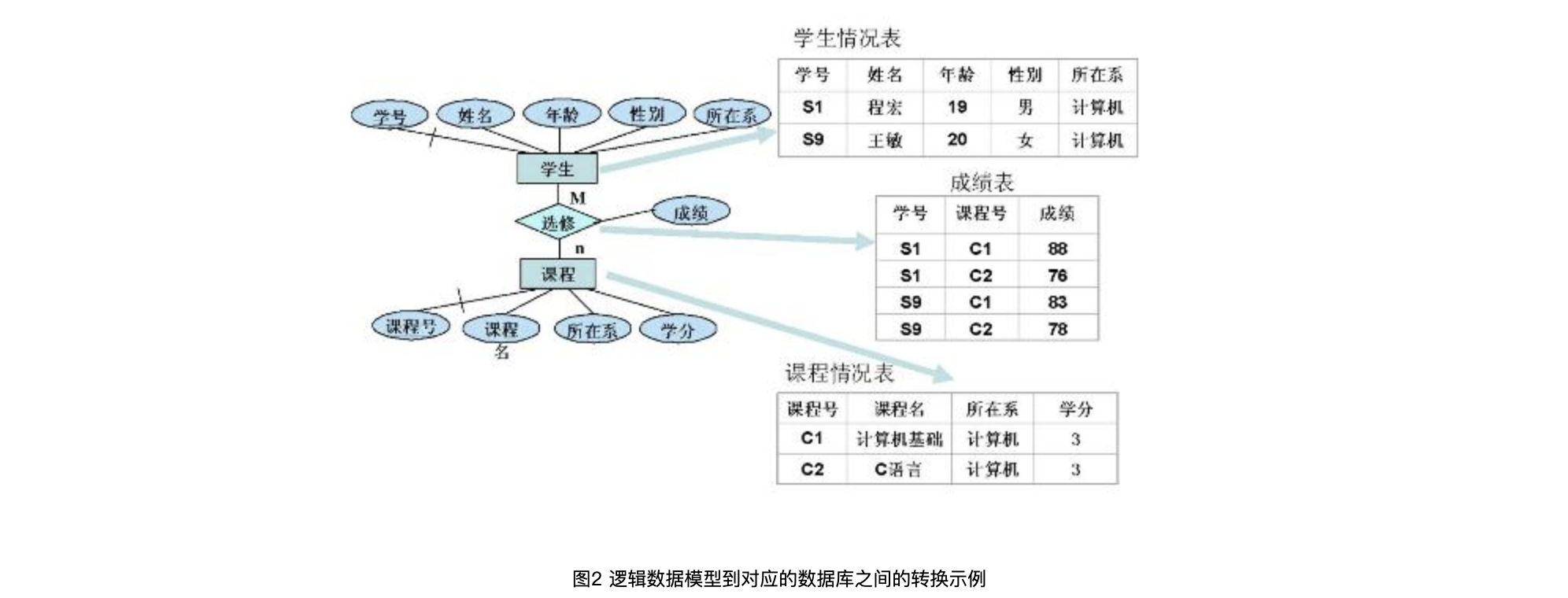
1、掌握关系模型概念和 SQL 语言。
数据模型主要有两大类,分别是概念数据模型(实体一联系模型)和基本数据模型(结构数据模型)。
概念数据模型是按照用户的观点来对数据和信息建模,主要用于数据库设计。概念模型主要用实体一联系方法(Entity- Relationship Approach)表示,所以也称 E-R 模型。
基本数据模型是按照计算机系统的观点来对数据和信息建模,主要用于 DBMS 的实现。基本数据模型是数据库系统的核心和基础。基本数据模型通常由数据结构、数据操作和完整性约束三部分组成。其中数据结构是对系统静态特性的描述,数据操作是对系统动态特性的描述,完整性约是一组完整性规则的集合。
常用的基本数据模型有层次模型、网状模型、关系模型和面向对象模型。
层次模型用树形结构表示实体类型及实体间的联系。层次模型的优点是记录之间的联系通过指针来实现,査询效率较高。层次模型的缺点是只能表示 1:n 联系,虽然有多种辅助手段实现 m:n 联系,但比较复杂,用户不易掌握。由于层次顺序的严格和复杂,导致数据的査询和更新操作很复杂,应用程序的编写也比较复杂。
网状模型用有向图表示实体类型及实体间的联系。网状模型的优点是记录之间的联系通过指针实现,m:n 联系也容易实现,査询效率高。其缺点是编写应用程序的过程比较复杂程序员必须熟悉数据库的逻辑结构。
关系模型用表格结构表达实体集,用外键表示实体间的联系。其优点有:
(1)建立在严格的数学概念基础上
(2)概念(关系)单一,结构简单、清晰,用户易懂易用
(3)存取路径对用户透明,从而数据独立性、安全性好,简化数据库开发工作
| 分类 | 含义 |
|---|---|
| DDL数据定义语言 | 负责数据库定义、数据库对象定义。由create,alter,drop |
| DML数据操作语言 | 负责绝对数据库对象的操作,CRUD增删改查 |
| DCL数据控制语言 | 负责数据库权限访问控制,grant和revoke两个指令组成 |
| TCL事务控制语言 | 负责处理acid事物,支持commit、rollback指令 |
2、掌握关系数据库设计方法。
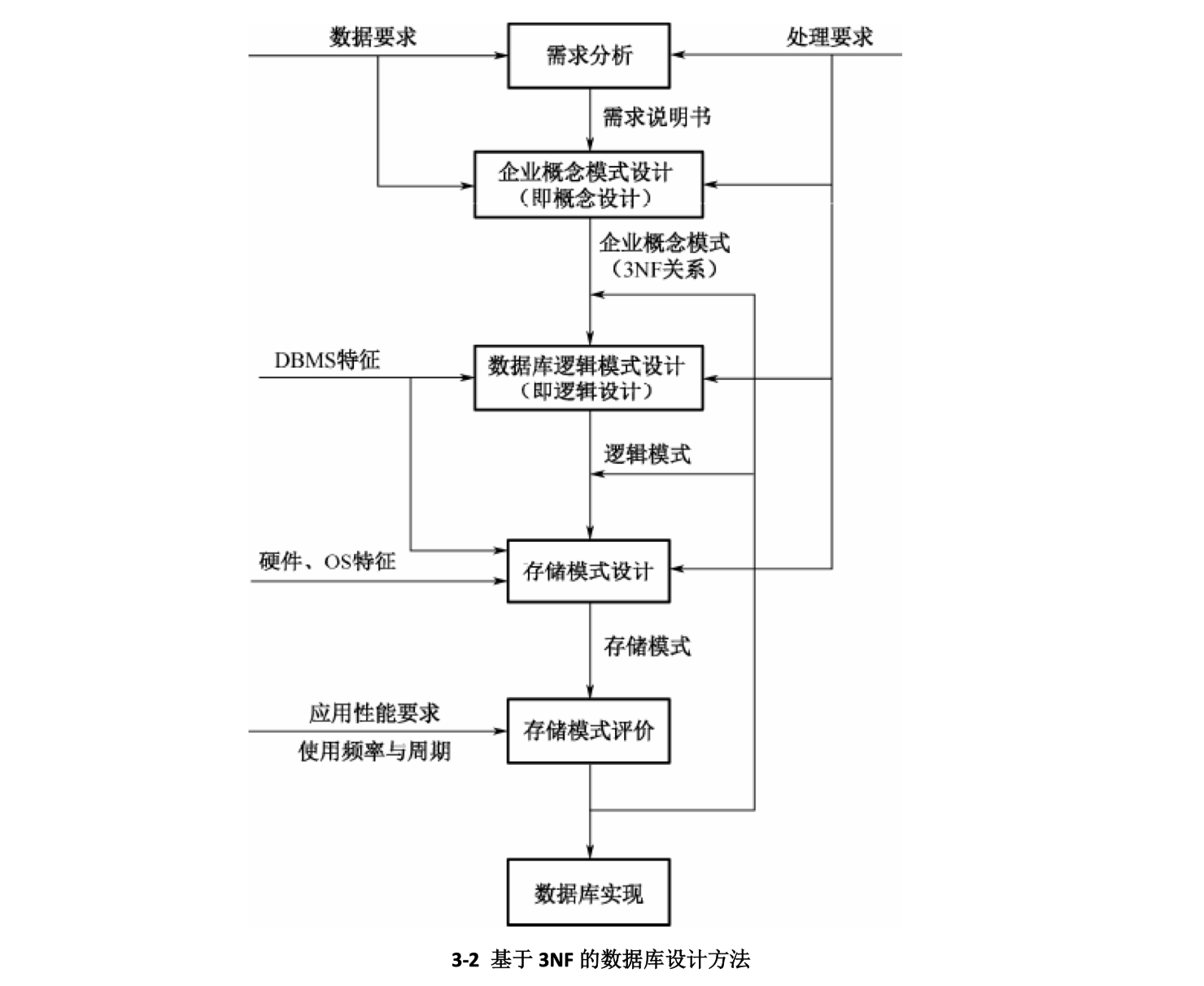
目前已有的数据库设计方法可分为四类,即直观设计法、规范设计法、计算机辅助设计法和自动化设计法。
直观设计法又称单步逻辑设计法,它依赖于设计者的知识、经验和技巧,缺乏工程规范的支持和科学根据,设计质量也不稳定,因此越来越不适应信息管理系统发展的需要。为了改变这种状况,1978 年 10 月来自 30 多个欧美国家的主要数据库专家在美国新奥尔良市专门讨论了数据库设计问题,提出了数据库设计规范,把数据库设计分为需求分析、概念结构设计、逻辑结构设计和物理结构设计 4 个阶段。
目前,常用的规范设计方法大多起源于新奥尔良方法,如基于 3NF 的设计方法、LRA 方法、面向对象的数据库设计方法及基于视图概念的数据库设计方法等。
3、掌握关系数据库索引的概念和使用方法。
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
索引的一个主要目的就是加快检索表中数据,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构。
搜索码。它表示的是记录各种字符段的一个集合,它可以是一个或者是多个字符段的任意序列组合,并不是惟一的一个标识记录。
数据目录项。即为索引的相关元素,在建立索引的过程中,数据目录项一般具有各种不同的选择方式。
记录ID。每一个/段索引在存储内容中惟一的一个标识符。
唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引。当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。
主键索引
数据库表经常有一列或多列组合,其值唯一标识表中的每一行。该列称为表的主键。在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚集索引
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。聚集索引和非聚集索引的区别,如字典默认按字母顺序排序,读者如知道某个字的读音可根据字母顺序快速定位。因此聚集索引和表的内容是在一起的。如读者需查询某个生僻字,则需按字典前面的索引,举例按偏旁进行定位,找到该字对应的页数,再打开对应页数找到该字。这种通过两个地方而查询到某个字的方式就如非聚集索引。
索引列
可以基于数据库表中的单列或多列创建索引。多列索引可以区分其中一列可能有相同值的行。如果经常同时搜索两列或多列或按两列或多列排序时,索引也很有帮助。例如,如果经常在同一查询中为姓和名两列设置判据,那么在这两列上创建多列索引将很有意义。
4、掌握关系数据库查询处理与查询优化方法。
1、创建索引
对于查询占主要的应用来说,索引显得尤为重要。很多时候性能问题很简单的就是因为我们忘了添加索引而造成的,或者说没有添加更为有效的索引导致。如果不加索引的话,那么查找任何哪怕只是一条特定的数据都会进行一次全表扫描,如果一张表的数据量很大而符合条件的结果又很少,那么不加索引会引起致命的性能下降。但是也不是什么情况都非得建索引不可,比如性别可能就只有两个值,建索引不仅没什么优势,还会影响到更新速度,这被称为过度索引。
2、复合索引
比如有一条语句是这样的:select * from users where area=’beijing’ and age=22;
如果我们是在area和age上分别创建单个索引的话,由于mysql查询每次只能使用一个索引,所以虽然这样已经相对不做索引时全表扫描提高了很多效率,但是如果在area、age两列上创建复合索引的话将带来更高的效率。如果我们创建了(area, age, salary)的复合索引,那么其实相当于创建了(area,age,salary)、(area,age)、(area)三个索引,这被称为最佳左前缀特性。因此我们在创建复合索引时应该将最常用作限制条件的列放在最左边,依次递减。
3、索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
4、使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
5、排序的索引问题
mysql查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
6、like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
7、不要在列上进行运算
select * from users where YEAR(adddate)<2007;
将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成
select * from users where adddate<‘2007-01-01’;
8、不使用NOT IN和<>操作
NOT IN和<>操作都不会使用索引将进行全表扫描。NOT IN可以NOT EXISTS代替,id<>3则可使用id>3 or id<3来代替。
5、掌握关系数据库事务概念和事务调度方法。
事务是将一组读写操作组合在一起形成一个逻辑单元。这些操作要么全部执行成功提交(commit),要么全部中止失败(abort,rollback),不会留下一个中间状态的烂摊子。所以,失败后程序可以安全的重试,分析原因等。 相反,如果没有对事务的支持,数据库可能持久化很多中间状态,留下无法解释的业务,开发人员处理起来也很麻烦。所以,事务是为了简化编程,提供数据安全/正确性/一致性。当然,任何便利都是有代价的,事务也有一些问题,所以NoSQL数据库,分布式数据库在某种程度上会弱化事务。有些甚至完全放弃事务。
ACID特性
谈到事务,都想到ACID。每个字母分别代表原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持久性 (Durability)。搞清楚了ACID,就相当于搞清楚了事务的精髓。
事物的调度分类
并行执行:多个事物是可以同时执行的
串行执行:一个事物在执行的时候另外的事物必须等到当前事物执行完才能执行
串行执行会让运行效率低下,而并行执行会破坏数据库的一致性
交叉事物的控制(并行执行事物的控制)
乐观控制(乐观锁)
1.每次访问数据的时候,不加锁,都看做是在做读操作,其他事物也能访问当前事物访问的数据。这样就会造成数据不一致性,所以数据库为了使得数据一致性得到保证,在并发的修改了数据之后,数据库会对相关的数据进行回滚。
2.特点
采用的是事后做回滚操作解决冲突问题
事物的数据回滚可能造成级联回滚
在读操作占大多数的情况下,采用乐观控制效率会高
悲观控制(悲观锁)
1.事物访问数据之前先对数据进行加锁,防止其他事物也访问当前的数据
2.特点
采用的是预防冲突发生的思想
采用悲观控制,除非死锁,否则事物肯定会成功
其他事物,在某些情况下也可以是读操作
悲观控制,就是严格的控制了其他事物对当前事物的访问,有效的避免了大量事物的回滚
锁(锁的实质:数据库对元素进行存取的许可证)
锁的分类
1.粒度:库锁,表锁,页锁,行锁 (粒度越大,并发性越差,开销越少;粒度越小,开销越大,并发越好)
2.强度
(1)排他锁(独占锁,写锁)
某个事物T占有了元素A的排他锁,其他事物对元素A的任何锁请求都不会被允许,直到事物T释放了锁
事物T可以对A元素做写操作,也可以做读操作
(2)共享锁(读锁)
某个事物T占有了元素A的共享锁,那么其他事物对元素A的共享锁请求可以成功,排他锁的请求会失败
事物T只能对元素A做读操作,不能做写操作
(3)更新锁
是解决了锁升级带来的死锁问题
一个事物在查询数据的时候对这个元素加“更新锁”,当真正到了修改的时候将“更新锁”升级为“排他锁”,如果查询完成之后,觉得对元素不进行修改,会将锁降级了“共享锁”。
(4)意向锁(能够解决加锁冲突)
T1事物对A表某一行加了共享锁,T2事物对A表加了排他锁,T2事物其实也隐含了对每一行的排他锁,这样就会造成加锁冲突。
解决加锁层级上问题
分类:意向排他锁;意向共享锁
意向锁,在给表,页加锁的时候并不表明是排他,还是共享,只有到了真正要执行的行数据的时候才会真正表明是“意向共享锁”或者是“意向排他锁”
锁的相兼容性
1.一个元素可以加多个共享锁
2.一个元素只能加一个排他锁
3.一个元素不能同时加共享锁和排他锁
锁升级/降级
共享锁转成排他锁,锁升级
排他锁转成共享锁,锁降级
两段锁协议
主要解决了:冲突事物的可串行话,简化加锁算法
定义:增长阶段,事物只能加锁,不能释放锁;收缩阶段,事物只能解锁,不能获得锁
加锁导致问题
问题:1.事物阻塞,等待;2.死锁
事物各自持有对方想要的锁,并且都在相互等待对方释放锁
解决方式:
1.一次封锁法,事物一次就占据所有字资源,要么全部封锁,要么全不封锁
2.顺序加锁,定义锁的加锁顺序,只能这么来
3.时间戳
6、掌握数据库并发控制技术。
https://baijiahao.baidu.com/s?id=1663478291935672795&wfr=spider&for=pc
7、了解非关系数据库背景、特点和分类。
NOSQL 即 Not Only SQL,可直译“不仅仅是 SQL”,这项技术正在掀起一场全新的数据库革命性运动。
数据的模式包括多种类型,如层次模型、网状模型、关系模型等,而在实际应用过程中,几乎都是在用关系模型,主流的数据库系统都是关系型的。但随着互联网 web2.0 网站的兴起,传统的关系数据库在应付 web2.0 网站,特别是超大规模和高并发的 SNS 类型的 web2.0 纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。这也就使得 NOSQL 技术进入了人们的视野。
NOSQL 的出现打破了长久以来关系型数据库与 ACID 理论大一统的局面。NOSQL 数据存储不需要固定的表结构,通常也不存在连接操作。在大数据存取上具备关系型数据库无法比拟的性能优势。
关系型数据库中的表都是存储一些格式化的数据结构,每个元组字段的组成都一样,即使不是每个元组都需要所有的字段,但数据库会为每个元组分配所有的字段,这样的结构可以便于表与表之间进行连接等操作,但从另一个角度来说它也是关系型数据库性能瓶颈的个因素。而非关系型数据库以键值对存储,它的结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。
与关系型数据库相比,NOSQL 数据库具有以下几个优点:
1.易扩展
NOSQL 数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间,在架构的层面上带来了可扩展的能力
2.大数据量,高性能
NOSQL 数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般 MYSQL 使用 Query Cache,每次表一更新 Cache 就失效,它是一种大粒度的 Cache,在针对 web2.0 的交互频繁的应用,Cache 性能不高。而 NOSQL 的 Cache 是记录级的,是一种细粒度的 Cache,所以 NOSQL 在这个层面上来说性能就高很多了。
3.灵活的数据模型
NOSQL 无须事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个梦。这点在大数据量的 web2.0 时代尤其明显。
4.高可用
NOSQL 在不太影响性能的情况,就可以方便地实现高可用的架构。比如 Cassandra Hbase 模型,通过复制模型也能实现高可用。
当然,NOSQL 也存在很多缺点,例如,并未形成一定标准,各种产品层出不穷,内部混乱,各种项目还需时间来检验,缺乏相关专家技术的支持等。
对于非关系型数据库主要有四种数据存储类型:键值对存储(key-value),文档存储(document store),基于列的数据库(column-oriented),还有就是图形数据库(graph database)。